MLX、macOS Tahoe 26.2以降がインストールされたM5チップ搭載Macでニューラルアクセラレータを活用できるように
※本サイトは、アフィリエイト広告および広告による収益を得て運営しています。購入により売上の一部が本サイトに還元されることがあります。

MLX
AppleのMachine Learning Researchが「Exploring LLMs with MLX and the Neural Accelerators in the M5 GPU」を発表し、macOS Tahoe 26.2以降がインストールされたM5チップ搭載Macで、Apple Silicon向けに高度に調整されたオープンソースの配列フレームワーク「MLX」で、ニューラルアクセラレータを活用できるようになると説明しています。
ニューラルアクセラレータは、多くの機械学習ワークロードに不可欠な専用の行列乗算演算を提供し、Apple Silicon 上でさらに高速なモデル推論エクスペリエンスを実現すると説明しています。
数値シミュレーション、科学計算、機械学習など、幅広いアプリケーションに使用できるMLXには、テキストや画像の生成を含むニューラルネットワークのトレーニングと推論のサポートが組み込まれています。
MLXを使用すると、Apple Siliconデバイス上で大規模な言語モデルによるテキスト生成や微調整が容易になります。
M5チップで導入されたGPUニューラル・アクセラレータは、多くの機械学習ワークロードにとって極めて重要な専用の行列乗算演算を提供します。
MLXは、Metal 4で導入されたTensor Operations(TensorOps)とMetal Performance Primitivesフレームワークを活用して、ニューラル・アクセラレータの機能をサポートします。
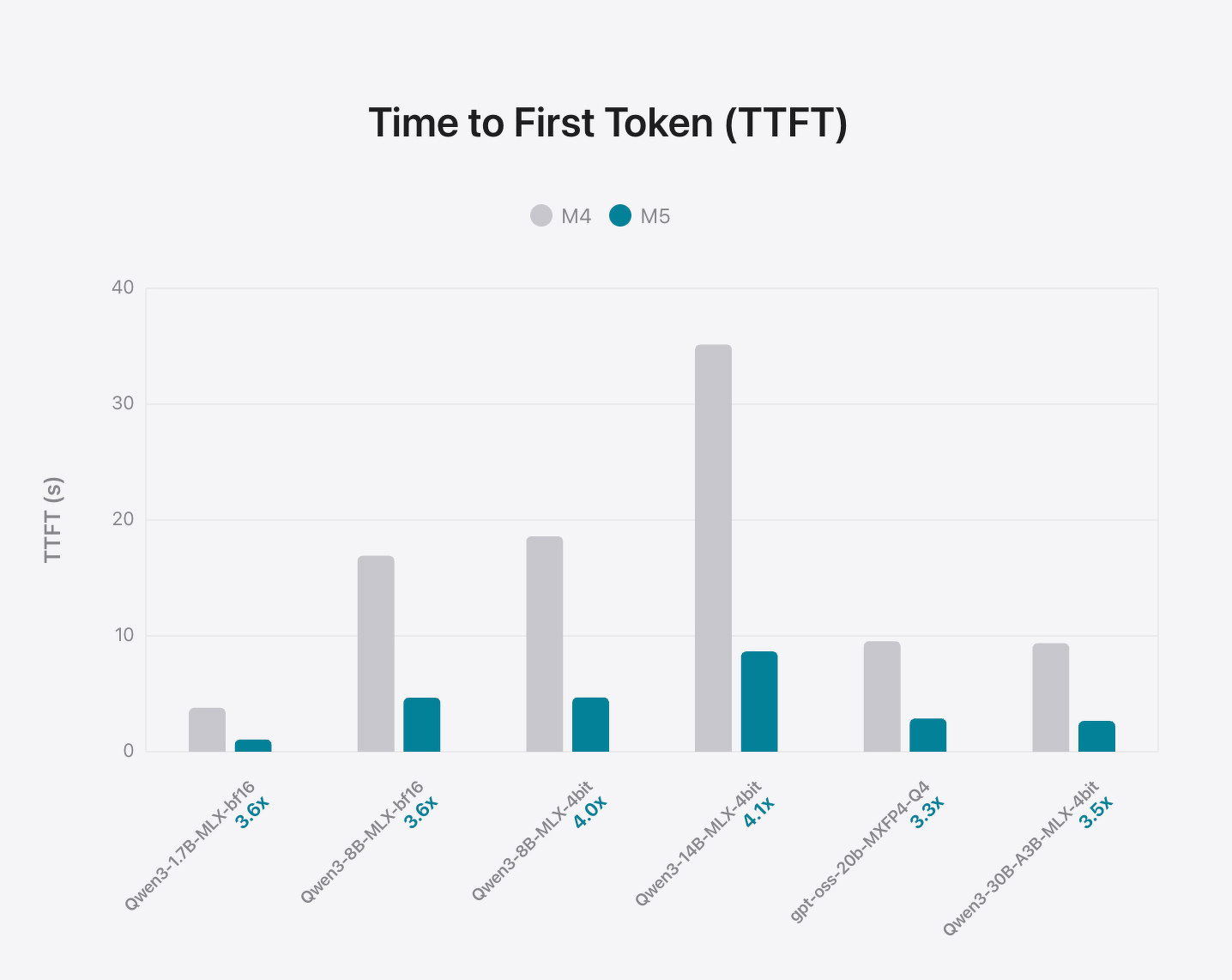
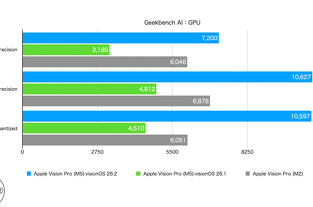
Time to First Token (TTFT)
LLM推論では、最初のトークン生成は計算量に大きく依存し、ニューラルアクセラレータを最大限に活用します。M5は、14Bの高密度アーキテクチャで最初のトークン生成までの時間を10秒未満、30BのMoEで3秒未満に短縮し、MacBook Pro上でこれらのアーキテクチャにおいて優れたパフォーマンスを実現します。
後続のトークン生成は、計算能力ではなくメモリ帯域幅によって制限されます。本記事でテストしたアーキテクチャでは、M5はメモリ帯域幅の広さ(M4は120GB/秒、M5は28%高い153GB/秒)により、M4と比較して19~27%のパフォーマンス向上を実現しています。
メモリフットプリントに関しては、MacBook Pro 24GBはBF16精度で8B、またはMoE 4ビット量子化で30Bを容易に格納でき、どちらのアーキテクチャでも推論ワークロードを18GB未満に抑えることができます。