Appleのデバイス内およびサーバー基盤言語モデルのアップデート
※本サイトは、アフィリエイト広告および広告による収益を得て運営しています。購入により売上の一部が本サイトに還元されることがあります。

Foundation Language Models
AppleのMachine Learning Researchが、WWDC25において「Updates to Apple's On-Device and Server Foundation Language Models」を公開し、最新ソフトウェアリリースのApple Intelligence機能を強化するために特別に開発された、新世代の言語基盤モデルを発表しています。
また、アプリ開発者がApple Intelligenceの中核を成すデバイス上の基盤言語モデルに直接アクセスできる、新しい「Foundation Models Framework」も発表しています。
これらの生成モデルは、Appleのプラットフォーム全体に統合された幅広いインテリジェント機能の基盤となるように構築されており、これらのモデルは、ツールの使用と推論能力が向上し、画像とテキストの入力を理解し、より高速かつ効率的に動作し、15言語をサポートするように設計されています。
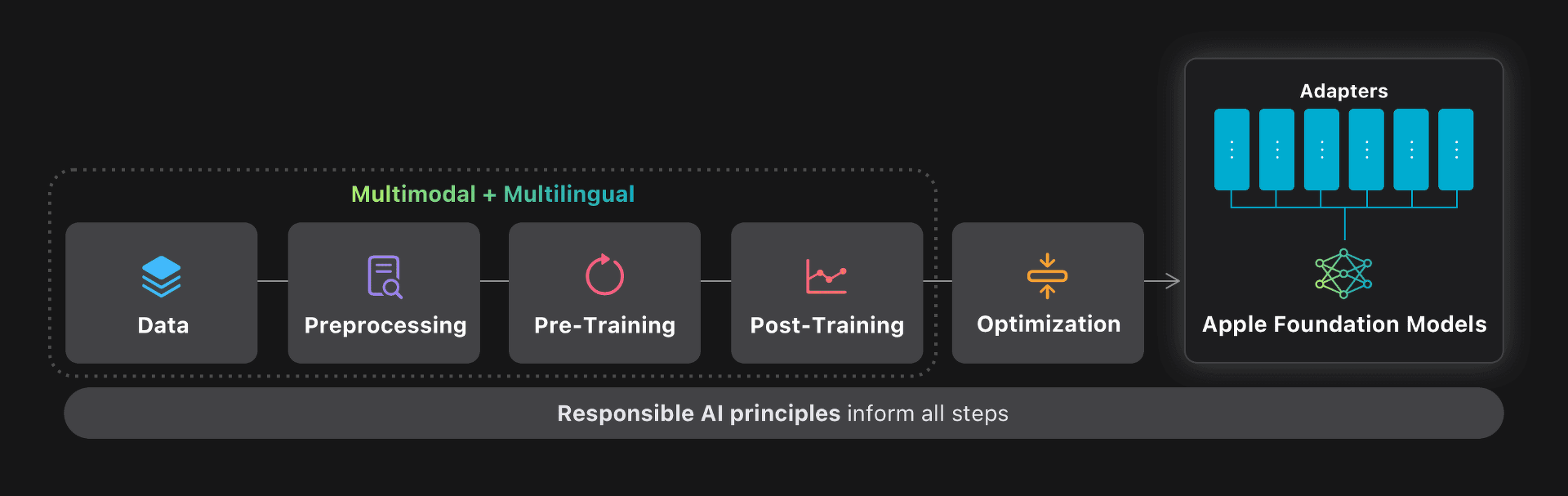
Apple 基盤モデルのモデリングの概要
最新の基盤モデルは、Apple Silicon上で効率的に動作するように最適化されており、コンパクトな約30億パラメータのモデルに加え、Private Cloud Compute向けにカスタマイズされた革新的なアーキテクチャを備えた、エキスパート混合型のサーバーベースモデルが含まれています。
これら2つの基盤モデルは、Appleがユーザーをサポートするために作成した、より大規模な生成モデルファミリーの一部です。
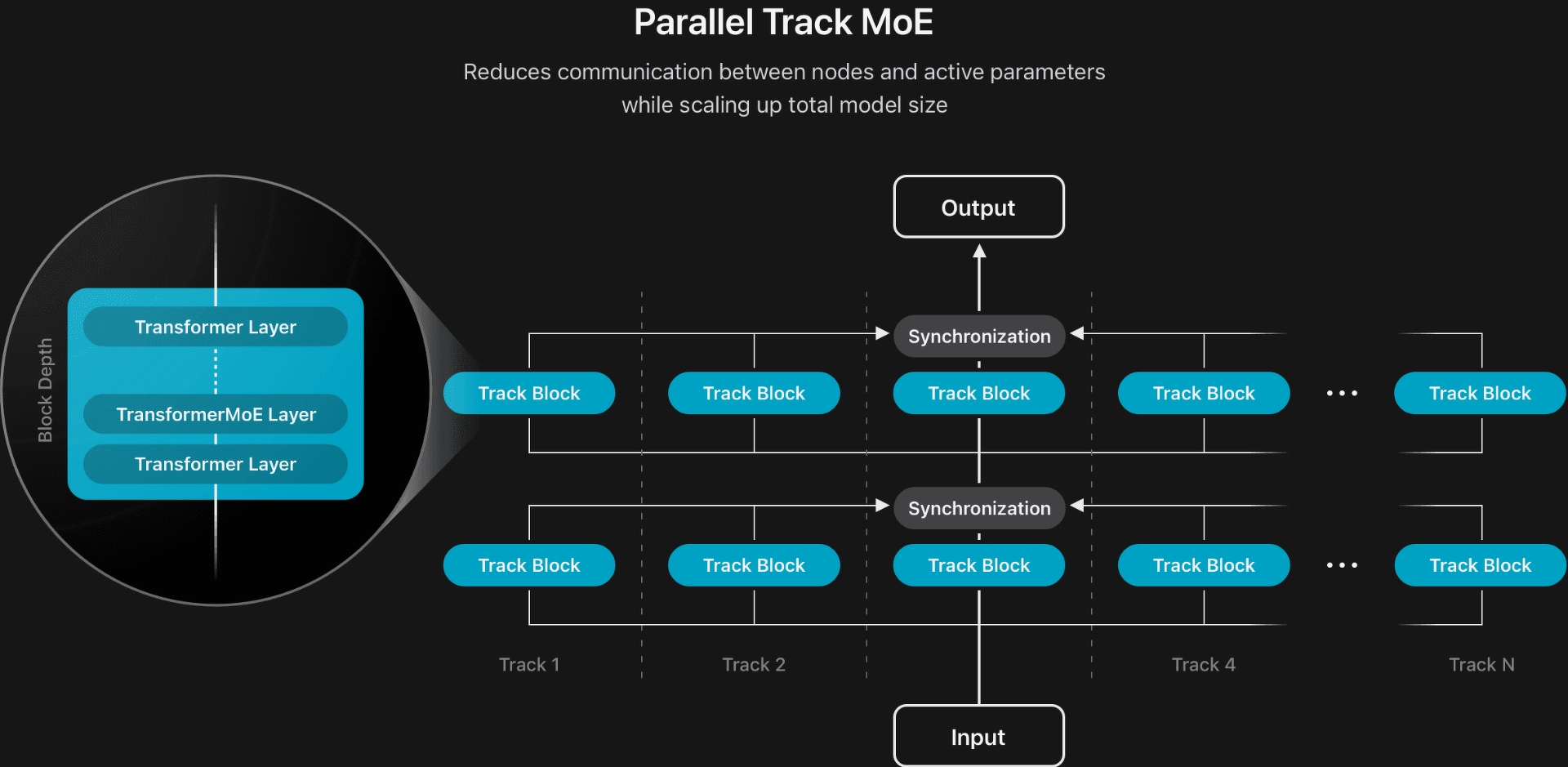
PT-MoEアーキテクチャの図
幅広いパフォーマンスと導入要件に対応するため、オンデバイスモデルとサーバーモデルの両方を開発し、オンデバイスモデルは効率性を重視し、Apple Silicon向けにカスタマイズされており、最小限のリソース使用量で低レイテンシの推論を実現します。
一方、サーバーモデルは、より複雑なタスクに対応する高い精度とスケーラビリティを実現するように設計されています。これらを組み合わせることで、多様なアプリケーションに適応可能な補完的なソリューションスイートが実現します。
新しいモデル アーキテクチャを開発することで、両方のモデルの効率を改善しました。デバイス上のモデルでは、モデル全体を 5:3 の深さ比で 2 つのブロックに分割しました。
ブロック 2 のすべてのキー値 (KV) キャッシュは、ブロック 1 の最終レイヤーで生成されたキャッシュと直接共有されるため、KV キャッシュ メモリの使用量が 37.5% 削減され、最初のトークンまでの時間が大幅に改善されました。
また、並列トラック混合エキスパート (PT-MoE) 設計を導入することで、サーバー モデルの新しいアーキテクチャも開発しました。
このモデルは、トラックと呼ばれる複数の小さなトランスフォーマーで構成されており、トラック ブロックの入力と出力の境界でのみ同期が適用されます。
さらに、各トラック ブロックには独自の MoE レイヤー セットがあります。
トラックの独立性によって可能になるトラック レベルの並列処理と組み合わせることで、この設計により同期のオーバーヘッドが大幅に削減され、品質を損なうことなく低レイテンシを維持しながらモデルを効率的に拡張できるようになりました。
より長いコンテキスト入力をサポートするために、回転位置埋め込み(RoPE)を備えたスライディングウィンドウ型ローカルアテンション層と、位置埋め込みのないグローバルアテンション層(NoPE)を組み合わせたインターリーブアテンションアーキテクチャを設計しました。この構成により、長さの汎化が向上し、KVキャッシュサイズが削減され、長コンテキスト推論中のモデル品質が維持されます。
視覚機能を実現するために、大規模画像データで学習したビジョンエンコーダを開発しました。これは、豊富な特徴量を抽出するビジョンバックボーンと、特徴量をLLMのトークン表現に整合させるビジョン言語アダプタで構成されています。
サーバーモデルには10億パラメータの標準Vision Transformer (ViT-g) を使用し、デバイスへの実装には3億パラメータのより効率的なViTDet-Lバックボーンを使用しました。さらに、ローカルな詳細とより広範なグローバルコンテキストの両方を効果的にキャプチャして統合するために、標準ViTDetに新しいレジスタウィンドウ (RW) メカニズムを追加しました。
これにより、グローバルコンテキストとローカルな詳細の両方を効果的にキャプチャできます。
トレーニングデータ
Appleは、多様で高品質なデータを用いてモデルを学習させることに尽力していて、これには、出版社からライセンス供与を受けたデータ、公開またはオープンソースのデータセットからキュレーションしたデータ、そして当社のウェブクローラーであるApplebotによってクロールされた公開情報が含まれます。
基盤モデルの学習において、ユーザーの個人データやユーザーインタラクションは一切使用しません。さらに、特定のカテゴリーの個人を特定できる情報や、不適切な表現、危険なコンテンツを除外するためのフィルターを適用するなどの対策を講じています。
さらに、Appleは倫理的なウェブクロールに関するベストプラクティスを継続的に遵守しています。これには、広く採用されているrobots.txtプロトコルの遵守も含まれており、これによりウェブパブリッシャーは、Appleの生成基盤モデルの学習にコンテンツが利用されることをオプトアウトできます。ウェブパブリッシャーは、SiriやSpotlightの検索結果に表示されながらも、Applebotが閲覧できるページとその利用方法をきめ細かく制御できます。
テキストデータ
上記のオプトアウトを尊重しつつも、モデルの事前トレーニングデータの大部分は、Applebot がクロールしたウェブコンテンツから引き続き取得しました。これらのコンテンツは数千億ページに及び、幅広い言語、ロケール、トピックを網羅しています。ウェブのノイズの多い性質を考慮し、Applebot は高度なクロール戦略を採用し、高品質で多様なコンテンツを優先しています。特に、高忠実度の HTML ページをキャプチャすることに重点を置きました。これにより、テキストと構造化メタデータの両方がデータセットに付加され、メディアと周囲のテキストコンテンツが整合されます。関連性と品質を向上させるため、システムはドメインレベルの言語識別、トピック分布分析、URL パスパターンのヒューリスティックなど、複数のシグナルを活用しました。
ドキュメントや最新のウェブサイトからコンテンツを正確に抽出するために、特別な配慮を行いました。ヘッドレスレンダリングによりドキュメントコレクションを強化し、ウェブアーキテクチャからデータを抽出するために不可欠なフルページ読み込み、動的コンテンツインタラクション、JavaScript実行を可能にしました。動的コンテンツとユーザーインタラクションに依存するウェブサイトでは、複雑なページから意味のある情報を確実に抽出するために、完全なページ読み込みとインタラクションシミュレーションを可能にしました。また、特にドメイン固有のドキュメントにおいて、従来のルールベースの手法よりも優れたパフォーマンスを発揮することが多い大規模言語モデル(LLM)を抽出パイプラインに組み込みました。
高度なクローリング戦略に加え、トレーニングデータの規模と多様性を大幅に拡大し、一般分野、数学、プログラミングに関する高品質なコンテンツをより多く取り入れました。また、多言語サポートを新たな言語に拡張し、今年後半に提供開始予定です。
高品質なフィルタリングは、モデル全体のパフォーマンスにおいて極めて重要な役割を果たすと考えています。過度に積極的なヒューリスティックルールへの依存を減らし、モデルベースのフィルタリング手法をより多く取り入れることで、データフィルタリングパイプラインを改良しました。モデル情報に基づくシグナルを導入することで、より有益なコンテンツを保持できるようになり、より大規模で高品質な事前学習データセットを実現しました。
画像データ
モデルを強化し、Apple Intelligence 機能の視覚的理解機能を有効にするために、高品質のライセンスデータと公開されている画像データを活用して、事前トレーニング パイプラインに画像データを導入しました。
ウェブクロール戦略を使用して、対応する代替テキストを持つ画像のペアを調達しました。法令遵守のためのフィルタリングに加えて、画像とテキストの配置を含むデータ品質に基づいてフィルタリングしました。重複除去後、このプロセスにより 100 億を超える高品質の画像とテキストのペアが生成されました。さらに、クロールされたドキュメントから、元のテキスト コンテキストで画像を保持することにより、画像とテキストのインターリーブ データを作成しました。品質と法令遵守に基づいてフィルタリングした後、5 億 5,000 万枚を超える画像を含む 1 億 7,500 万のインターリーブされた画像とテキストのドキュメントが生成されました。ウェブクロールされた画像とテキストのペアは一般に短く、画像の視覚的な詳細を包括的に説明していないことが多いため、合成画像キャプション データを使用して、より豊富な説明を提供しました。キーワードから段落レベルの包括的な説明まで、さまざまな詳細レベルで高品質のキャプションを提供できる社内用画像キャプション モデルを開発し、事前トレーニング段階全体で使用した 50 億を超える画像とキャプションのペアを生成しました。
モデルのテキストリッチな視覚理解能力を向上させるため、PDF、文書、原稿、インフォグラフィック、表、グラフなど、様々なテキストリッチなデータセットを、ライセンスデータ、ウェブクローリング、社内合成を通じて収集しました。そして、画像データからテキストを抽出し、書き起こしと質問と回答のペアを生成しました。
最適化
過去 1 年間で、Apple Intelligence の機能を拡張し、品質の向上を図るとともに、デバイス上およびサーバー モデルの推論効率を高め、電力消費を削減してきました。
デバイス上のモデルは、学習可能な重みクリッピングと重み初期化を組み合わせた量子化考慮型学習(QAT)を用いて、重みあたり2ビット(bpw)に圧縮しました。サーバーモデルは、ブロックベースのテクスチャ圧縮手法である適応型スケーラブルテクスチャ圧縮(ASTC)を用いて圧縮しました。ASTCは元々グラフィックスパイプライン向けに開発されましたが、モデル圧縮にも有効であることが分かっています。ASTCの解凍は、Apple GPUの専用ハードウェアコンポーネントを用いて実装されており、追加の計算オーバーヘッドを発生させることなく重みをデコードできます。
両モデルとも、埋め込みテーブルを重みあたり4ビットに量子化しました。オンデバイスモデルではQATを用いた基本重みとの結合学習、サーバーモデルでは学習後量子化を用いました。KVキャッシュは重みあたり8ビットに量子化されました。その後、追加データを用いて低ランクアダプターを学習し、これらの圧縮ステップによって失われた品質を回復しました。これらの手法により、わずかな品質低下とわずかな改善が見られました。例えば、オンデバイスモデルではMGSMで約4.6%の品質低下、 MMLUで1.5%の品質向上が見られました。サーバーモデルではMGSMで2.7%の品質低下、MMLUで2.3%の品質低下が見られました。
Foundation Models Framework
新しいFoundation Modelsフレームワークにより、開発者は~3Bパラメータのデバイス内言語モデルを用いて、信頼性の高い製品品質のAI生成機能を開発できるようになります。
Apple Intelligenceの中核を成す~3B言語基盤モデルは、要約、エンティティ抽出、テキスト理解、精緻化、短い対話、クリエイティブコンテンツの生成など、多様なテキストタスクに優れています。ただし、一般的な世界知識を提供するチャットボットとして設計されたものではありません。アプリ開発者の皆様には、このフレームワークを活用して、アプリに合わせた便利な機能を開発することをお勧めします。
私たちのフレームワークのハイライトは、ガイド付き生成と呼ばれる、制約付きデコードに対する直感的なSwiftアプローチです。ガイド付き生成では、開発者は@GenerableSwift構造体または列挙型にマクロアノテーションを追加することで、豊富なSwiftデータ構造を直接操作できます。
これは、モデル、オペレーティングシステム、そしてSwiftプログラミング言語との垂直統合によって実現されます。まず、開発者が定義した型を標準化された出力形式仕様に変換するSwiftコンパイラマクロが実行されます。
モデルにプロンプトを出すと、フレームワークはプロンプトに応答形式を挿入します。モデルは、ガイド付き生成仕様に基づいて設計された特別なデータセットで事後学習されているため、その形式を理解し、それに準拠することができます。
次に、OSデーモンが、制約付きデコードと投機的デコードの高度に最適化された補完的な実装を採用することで、推論速度を向上させると同時に、モデルの出力が期待される形式に準拠していることを強力に保証します。これらの保証に基づいて、フレームワークはモデル出力からSwift型のインスタンスを確実に作成できます。これにより、アプリ開発者はSwift型システムを基盤とした、よりシンプルなコードを記述できるようになり、開発者エクスペリエンスが向上します。
ツール呼び出しにより、開発者は、モデルに特定の種類の情報ソースまたはサービスを提供するツールを作成することにより、~3B モデルの機能をカスタマイズできるようになります。
このフレームワークのツール呼び出しへのアプローチは、ガイド付き生成に基づいています。開発者はシンプルなTool Swiftプロトコルの実装を提供し、フレームワークは並列および直列ツール呼び出しの潜在的に複雑な呼び出しグラフを自動的かつ最適に処理します。ツール使用データを用いたモデル事後学習により、このフレームワーク機能におけるモデルの信頼性が向上しました。
アプリ開発者がデバイス上のモデルを最大限に活用できるよう、フレームワークを綿密に設計しました。ランク3B以下のモデルに全く新しいスキルを学習させる必要がある特殊なユースケース向けに、ランク32のアダプタを学習するためのPythonツールキットも提供しています。
このツールキットで生成されるアダプタは、Foundation Modelsフレームワークと完全な互換性があります。ただし、アダプタはベースモデルが新しいバージョンになるたびに再学習する必要があります。そのため、ベースモデルの機能を徹底的に調査した上で、高度なユースケース向けにアダプタの導入を検討することをお勧めします。
評価
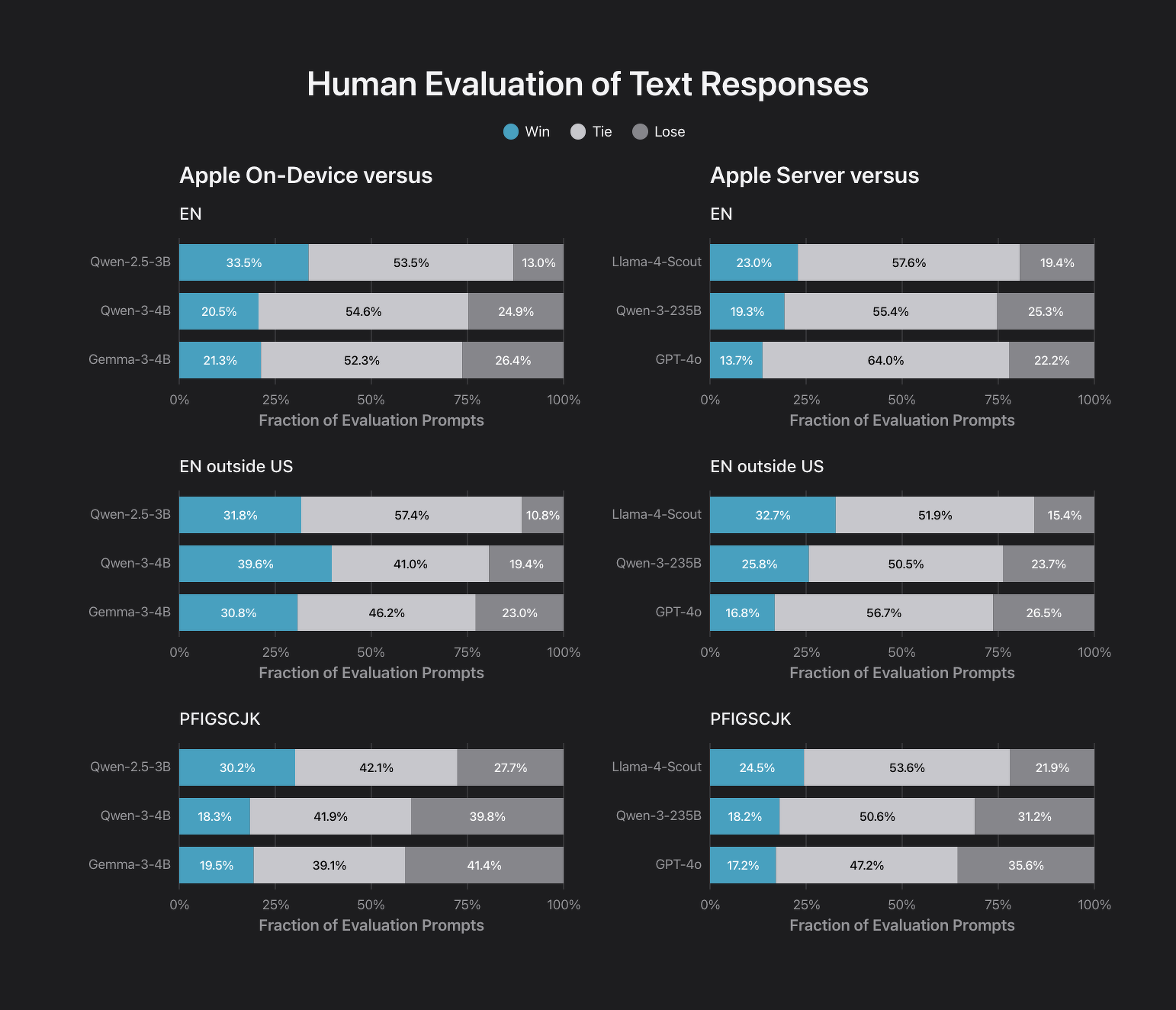
テキスト応答の人間による評価
デバイス上およびサーバーベースのモデルの品質評価は、オフラインで人間の採点者を用いて実施しました。評価項目は、分析的推論、ブレインストーミング、チャット、分類、クローズドQ&A、コーディング、クリエイティブライティング、抽出、数学的推論、オープンQ&A、リライト、要約、ツール使用といった、標準的な基礎言語および推論能力です。
モデルのサポートを他の言語とロケールに拡大するにつれ、評価タスクセットもロケール固有に拡張しました。人間の採点者が、そのロケールのユーザーにとってネイティブに聞こえる回答を生成できるモデルの能力を評価しました。
例えば、イギリスのユーザーからの英語のスポーツに関する質問に回答するモデルは、「サッカー」よりも「フットボール」の方が現地で適切な用語であると認識することが期待されます。採点者は、ローカライズされていない用語や不自然なフレーズなど、モデルの回答にいくつかの問題点をフラグ付けすることができました。ロケール固有の評価では、米国英語ロケールと同様のカテゴリが使用されましたが、数学やコーディングなど、本質的にロケールに依存しない技術分野は除外されました。
オンデバイスモデルは、全ての言語において、やや規模の大きいQwen-2.5-3Bに対して良好なパフォーマンスを示し、英語においては、より規模の大きいQwen-3-4BおよびGemma-3-4Bに対しても競争力があることがわかりました。
サーバーベースモデルは、Llama-4-Scoutに対して良好なパフォーマンスを示しました。Llama-4-Scoutの総サイズと有効パラメータ数はサーバーベースモデルと同等ですが、Qwen-3-235Bや独自仕様のGPT-4oといったより規模の大きいモデルには劣っています。
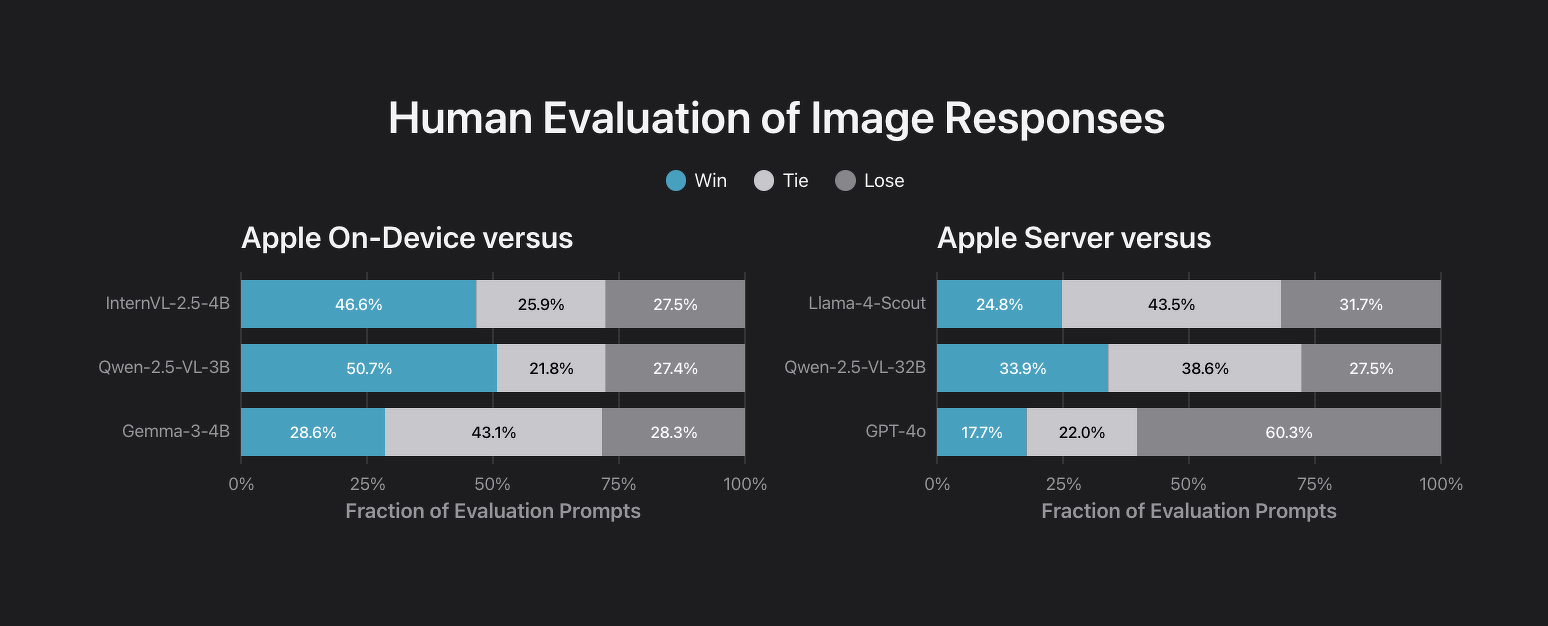
画像反応の人間による評価
モデルのサポートが画像モダリティに拡張されたため、画像と質問のペアの評価セットを使用して画像理解機能を評価しました。
この評価セットには、テキスト評価セットと同様のカテゴリに加えて、テキストが豊富な画像についてモデルが推論することを要求するインフォグラフィックなどの画像固有のカテゴリが含まれていました。
デバイス上のモデルを同様のサイズのビジョンモデル、つまり InternVL-2.5-4B、Qwen-2.5-VL-3B-Instruct、および Gemma-3-4B と比較し、サーバーモデルを Llama-4-Scout、Qwen-2.5-VL-32B、および GPT-4o と比較しました。
Apple のデバイス上のモデルは、より大きな InternVL および Qwen に対して有利なパフォーマンスを示し、Gemma に対しては競争力があることがわかりました。
また、サーバーモデルは、推論 FLOPS の半分以下で Qwen-2.5-VL を上回りますが、Llama-4-Scout と GPT-4o には遅れをとります。
結論
Apple Intelligenceの中核を成す言語基盤モデルをより効率的かつ高機能なものにすることで、Appleのソフトウェアプラットフォーム全体に統合された幅広い便利な機能を、世界中のユーザーが様々な言語で利用できるようになることを大変嬉しく思います。
また、新しいFoundation Modelsフレームワークにより、アプリ開発者がデバイス上の言語基盤モデルに直接アクセスできるようになります。
アプリ開発者は、わずか数行のコードでアクセスできる、無料で利用可能なAI推論を活用し、わずか数行のコードでテキスト抽出や要約といった機能をアプリに組み込むことができます。
最新の基盤モデルは、プライバシーへの取り組みや責任あるAIアプローチなど、あらゆる段階でAppleのコアバリューに基づいて構築されています。